set.seed(20)
X <- rgamma(5000, shape = 1, rate = 1)
Y <- log(X)
hist(Y, breaks = "Scott", freq = FALSE)
curve(exp(x - exp(x)), from = min(Y), to = max(Y), n = 1000,
col = "red", lwd = 3, add = TRUE)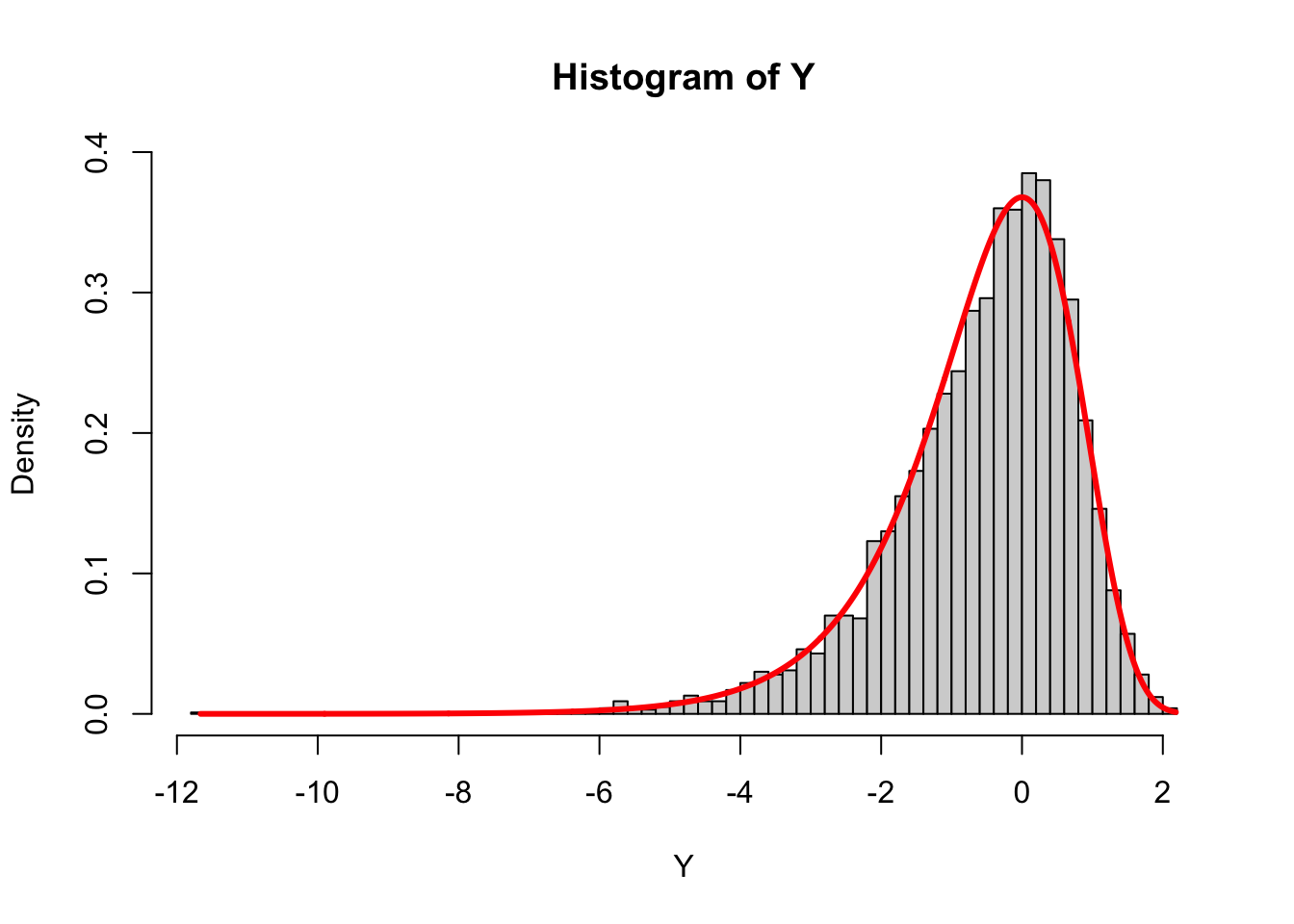
Due Thursday October 23 at 11:59 PM
Let \(X\) be a random variable, let \(g\) be a transformation, and consider the new random variable \(Y=g(X)\). If all we cared about was the mean of \(Y\), then LOTUS provides a nice shortcut for computing \(E(Y)=E[g(X)]\) directly. But often, we want to know the entire distribution of the new random variable \(Y\), not just the mean. Today we will learn how to calculate it.
In all that follows, \(X\) is continuous with pdf \(f_X\) and cdf \(F_X\). The goal in each case is to compute the density \(f_Y\) of the new random variable \(Y=g(X)\). The process for doing this is always the same:
This is the so-called “cdf method.”
Consider \(X\sim \text{Gamma}(1,\,1)\). This is the same as saying \(X\sim\text{Exponential}(1)\), which we saw in lecture on Monday.
n = 5000 draws of \(Y\). Plot a histogram, and add a line plot of the density you derived in part b. They should match!To begin, we know that \(\text{Range}(X)=[0,\,\infty)\) and
\[ \begin{aligned} F_X(x)&=1-e^{-x},&&x\geq0\\ f_X(x) &= e^{-x}, &&x\geq0. \end{aligned} \]
One of our math helpers displays the graph of the natural log and its inverse, the exponential. Consulting these, we note a few things:
The first property implies that \(\text{Range}(Y)=\mathbb{R}\). So fix arbitrary \(y\in \mathbb{R}\). The cdf of \(Y\) is
\[ \begin{aligned} F_Y(y)&=P(Y\leq y)\\ &=P(\ln X\leq y)\\ &=P(e^{\ln X}\leq e^y)\\ &=P\left(X\leq e^y\right)\\ &=F_X\left(e^y\right)\\ &=1-e^{-e^y}. \end{aligned} \]
Since the exponential function is order-preserving, we didn’t have to chage the inequality when we applied it to both sides. To get the pdf, take a derivative (using the chain rule!):
\[ f_Y(y)=F_Y'(y)=\frac{\text{d}}{\text{d} y}\left(1-e^{-e^y}\right)=0-(-e^y)e^{-e^y}=e^{y-e^y},\quad y\in\mathbb{R}. \]
If we compare this density to the histogram from a simulation, they agree:
set.seed(20)
X <- rgamma(5000, shape = 1, rate = 1)
Y <- log(X)
hist(Y, breaks = "Scott", freq = FALSE)
curve(exp(x - exp(x)), from = min(Y), to = max(Y), n = 1000,
col = "red", lwd = 3, add = TRUE)
Phew!
Consider \(X\sim\text{Unif}(-\pi/2,\,\pi/2)\).
n = 5000 draws of \(Y\). Plot a histogram, and add a line plot of the density you derived in part b. Can you get them to match?By construction, \(\text{Range}(X)=(-\pi/2,\,\pi/2)\). You can read more about the continuous uniform here, and we see see that the cdf is
\[ F_X(x) = \begin{cases} 0 & x\leq -\frac{\pi}{2}\\ \frac{x-\left(-\frac{\pi}{2}\right)}{\frac{\pi}{2}-\left(-\frac{\pi}{2}\right)} & -\frac{\pi}{2}<x<\frac{\pi}{2}\\ 1 & \frac{\pi}{2}\leq x. \end{cases} \]
So when \(-\frac{\pi}{2}<x<\frac{\pi}{2}\), we have
\[ F_X(x)=\frac{x+\frac{\pi}{2}}{\pi}=\frac{x}{\pi}+\frac{1}{2}. \]
The transformation is
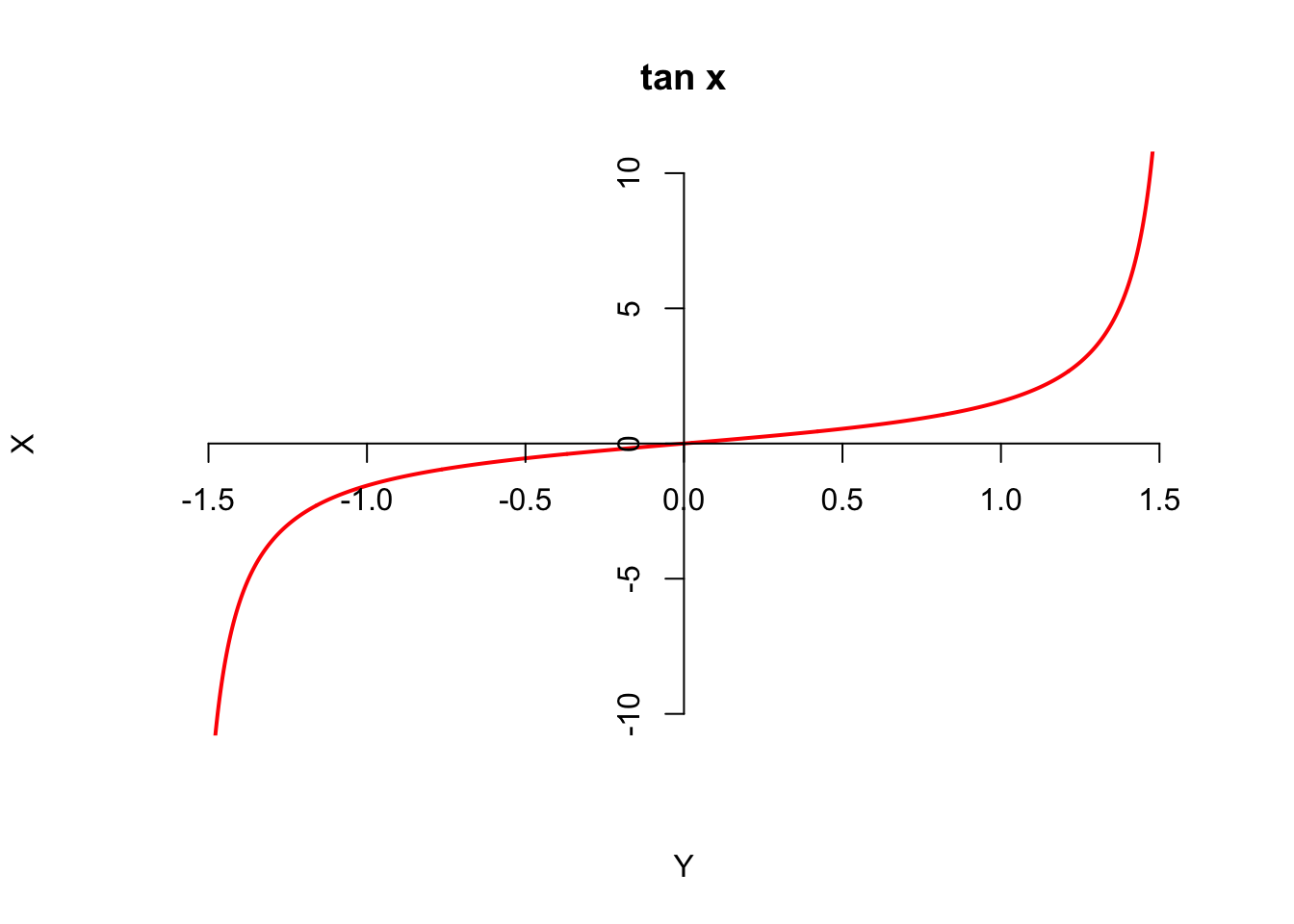
Again, strictly-increasing, and it maps to all real numbers. So \(\text{Range}(Y)=\mathbb{R}\). Now let’s fix arbitrary \(y\in\mathbb{R}\) and find the cdf:
\[ \begin{aligned} F_Y(y)&=P(Y\leq y)\\ &=P(\tan X\leq y)\\ &=P(X\leq \tan^{-1}y)\\ &=F_X(\tan^{-1}y)\\ &=\frac{\tan^{-1}y}{\pi}+\frac{1}{2}. \end{aligned} \]
Take a derivative to get the pdf:
\[ f_Y(y) = F'_Y(y) = \frac{\textrm{d}}{\textrm{d}y} \left( \frac{\tan^{-1}y}{\pi}+\frac{1}{2} \right) = \frac{1}{\pi(1+y^2)},\quad y\in\mathbb{R}. \]
Rest assured that we did the math right, but you’d have a hard time verifying it with a simulation:
Here is the graph of the density we derived, and for reference I added the pdf of the standard normal distribution (bell curve):
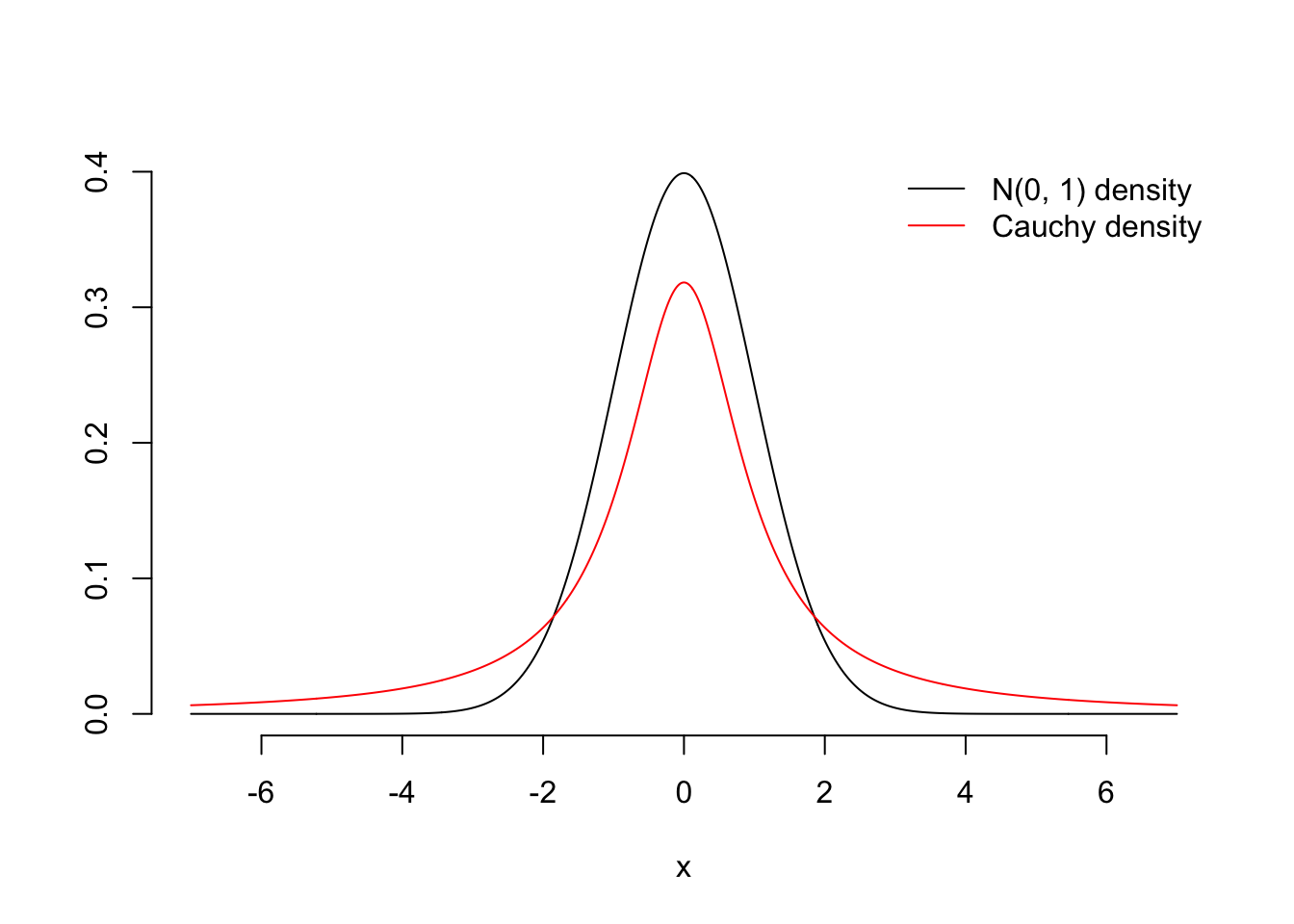
Compared to the bell curve, this new density has very heavy tails. They are so heavy in fact that this distribution does not have a finite mean or variance or any other moment. It is very ill-behaved, and it frequently surprises with extreme values far out in the tails. That’s why the histogram looks awful and always will.
This distribution we just derived is quite famous. It’s called the Cauchy distribution.
Consider \(X\sim \text{N}(0,\,1)\).
n = 5000 draws of \(Y\). Plot a histogram, and add a line plot of the density you derived in part b. They should match!We know that \(\text{Range}(X)=\mathbb{R}\) and that
\[ \begin{aligned} f_X(x)&=\frac{1}{\sqrt{2\pi}}e^{-x^2/2},&&x\in\mathbb{R}\\ F_X(x)&=\frac{1}{\sqrt{2\pi}}\int_{-\infty}^xe^{-t^2/2}\,\text{d}t,&&x\in\mathbb{R}. \end{aligned} \]
Newsflash: the cdf of the normal distribution is unknown. We can approximate it arbitrarily well using numerical methods, but we don’t actually have a clean formula for it. The integral above is simply intractable.
Anyway, the transformations involved here are again the exponential and the natural log, which we already saw in Task 1. Both are strictly-increasing. The exponential takes any real number and maps it to something strictly positive, so we see then that \(\text{Range}(Y)=(0,\,\infty)\). Fixing \(y>0\), we compute:
\[ \begin{align*} F_Y(y)&=P(Y\leq y)\\ &=P(e^X\leq y)\\ &=P\left(X\leq \ln y\right)\\ &=F_X\left(\ln y\right). \end{align*} \]
As such, the pdf is:
\[ \begin{aligned} f_Y(y) = F'_Y(y)&=\frac{\text{d}}{\text{d} y}F_X(\ln y)\\ &=F_X'(\ln y)\frac{\text{d}}{\text{d}y}\ln y\\ &=f_X(\ln y)\frac{1}{y}\\ &=\frac{1}{\sqrt{2\pi}}e^{-(\ln y)^2/2}\frac{1}{y},&&y>0. \end{aligned} \]
This matches with a simulation:
set.seed(20)
X <- rnorm(5000)
Y <- exp(X)
hist(Y, breaks = "Scott", freq = FALSE)
curve(dnorm(log(x)) / x, from = min(Y), to = max(Y), n = 1000,
col = "red", lwd = 3, add = TRUE)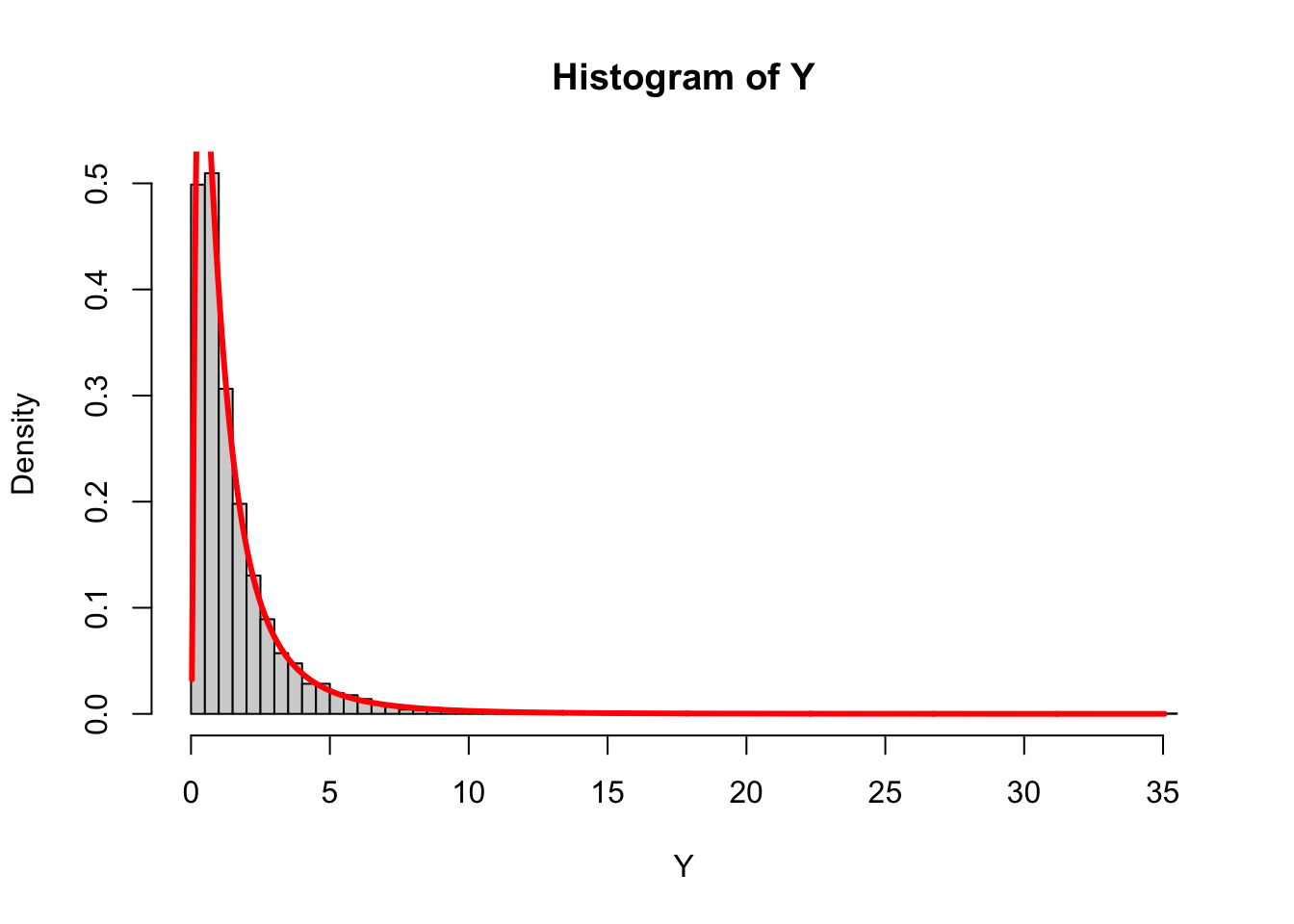
The distribution we derived here is an example of the log-normal distribution.
Given \(X\sim f_X\), we want the density of \(Y=g(X)\). In the three examples, you followed the same basic steps:
The basic template can be neatly summarized with the so-called change-of-variables formula, which tells you how to compute the density of \(Y\) using the density of \(X\) and the transformation \(g\):
\[ f_Y(y)=f_X\left(g^{-1}(y)\right) \left|\frac{\text{d}}{\text{d} y}g^{-1}(y)\right|,\quad y\in\text{Range}(Y). \]
Assume…
There are two cases:
Strictly increasing
If \(g\) is strictly increasing, then \(g^{-1}\) is strictly increasing also. This means that \(\frac{\text{d}}{\text{d} y}g^{-1}(y)\) must be positive for all \(y\)! It also means that \(g^{-1}\) is order-preserving. If \(a\leq b\), then \(g^{-1}(a)\leq g^{-1}(b)\).
Fix arbitrary \(y\in\text{Range}(Y)\). Then:
\[ \begin{aligned} F_Y(y) &= P(Y\leq y) \\ &= P\left(g(X)\leq y\right) \\ &= P\left(X\leq g^{-1}(y)\right) \\ &= F_X\left(g^{-1}(y)\right) . \end{aligned} \]
Taking a derivative and applying the chain rule gives
\[ \begin{aligned} f_Y(y) &= \frac{\text{d}}{\text{d} y}F_X\left(g^{-1}(y)\right) \\ &= f_X\left(g^{-1}(y)\right)\underbrace{\frac{\text{d}}{\text{d} y}g^{-1}(y)}_{\text{positive!}} \\ &= f_X\left(g^{-1}(y)\right) \left|\frac{\text{d}}{\text{d} y}g^{-1}(y)\right|. \end{aligned} \]
Strictly decreasing
If \(g\) is strictly decreasing, then \(g^{-1}\) is strictly decreasing also. This means that \(\frac{\text{d}}{\text{d} y}g^{-1}(y)\) must be negative for all \(y\)! It also means that \(g^{-1}\) is order-reversing. If \(a\leq b\), then \(g^{-1}(a)\geq g^{-1}(b)\).
Fix arbitrary \(y\in\text{Range}(Y)\). Then:
\[ \begin{aligned} F_Y(y) &= P(Y\leq y) \\ &= P\left(g(X)\leq y\right) \\ &= P\left(X> g^{-1}(y)\right) \\ &= 1-P\left(X\leq g^{-1}(y)\right) \\ &= 1-F_X\left(g^{-1}(y)\right) . \end{aligned} \] Taking a derivative and applying the chain rule gives
\[ \begin{align*} f_Y(y) &= \frac{\text{d}}{\text{d} y}[1-F_X\left(g^{-1}(y)\right)] \\ &= {\color{red}-}f_X\left(g^{-1}(y)\right)\underbrace{\frac{\text{d}}{\text{d} y}g^{-1}(y)}_{\text{negative!}} \\ &= f_X\left(g^{-1}(y)\right) \left|\frac{\text{d}}{\text{d} y}g^{-1}(y)\right|. \end{align*} \]
Either way, we got to the same place.
Let \(X\) be an absolutely continuous random variable with pdf \(f_X\), let \(a,\,b\in\mathbb{R}\) be non-zero constants, and consider the new random variable \(Y=aX+b\).
We know from lecture that \(E(Y)=E(aX+b)=aE(X)+b\) and \(\text{var}(Y)=\text{var}(aX+b)=a^2\text{var}(X)\).
If \(g(x)=ax+b\) is the linear transformation, then the inverse transformation and its derivative are
\[ \begin{align*} g^{-1}(y)&=\frac{y-b}{a}\\ \frac{\text{d}}{\text{d} y}g^{-1}(y)&=\frac{1}{a}, \end{align*} \]
and the change-of-variables formula gives:
\[ f_Y(y)=f_X\left(\frac{y-b}{a}\right)\frac{1}{|a|}. \]
If \(X\sim\text{N}(0,\,1)\), then we know from lecture that \(E(X)=0\), \(\text{var}(X)=1\), and
\[ f_X(x)=\frac{1}{\sqrt{2\pi}}\exp\left(-\frac{1}{2}x^2\right),\quad x\in\mathbb{R}. \]
A new random variable \(Y=aX+b\) has
\[ E(Y)=aE(X)+b=a\cdot 0+b=b, \]
and
\[ \text{var}(Y)=a^2\text{var}(X)=a^2\cdot 1=a^2, \]
and
\[ f_Y(y)=\frac{1}{|a|}\frac{1}{\sqrt{2\pi}}\exp\left(-\frac{1}{2}\left(\frac{x-b}{a}\right)^2\right)=\frac{1}{\sqrt{2\pi a^2}}\exp\left(-\frac{1}{2}\frac{\left(x-b\right)^2}{a^2}\right). \]
So \(Y\sim \text{N}(b,\, a^2)\). That’s where the general normal comes from: you apply a linear transformation to the standard normal.